数据结构-树
鸣谢·B站UP主蓝不过海呀精彩的课程 本文为课程的笔记
树
Base
- 父节点(双亲节点) 根节点无双亲 / 孩子
- 有同一个父结点 为 兄弟
- 祖先 向上推至根节点 都为其祖先
- 子孙
树的定义:n 个结点构成的优先集合
n = 0 时称为空树 n > 0 时 有且仅有一个根节点 其余结点可分为 m 个不相交子集
- 树的高度 = 树的深度 = 树的层数 = 1
- 结点的深度:他所在的层次(从上往下数)
- 结点的高度:以他为根的字数的层数
- 结点的度:孩子的个数(分支的个数) 度为0的结点为叶节点
- 树的度:树中结点的最大度数
- 度为 m 的树与 m 叉树
- 相同点:树里面结点的度最多为m
- 不同点:
- 度为m的树至少要有一个结点的度等于m(对此时此刻情况的描述)
- m叉树所有结点的度可以都小于m,甚至可以是空树(一种约束 只限制最多有 m 个分支)
- 有序树与无序树(可调换)
- 路径从上往下 长度 = 经过边的个数
性质
节点数 n = 变数 + 1 = 所有结点度数之和 =
总结点数 n = 加到度为 k 的节点数 为叶节点数
m 叉树的第 i 层最多有$m^{i-1}$个结点(度为 m 的数也一样)
高度为 h 的 m 叉树最多有多少个结点(度为 m 的数也一样) $$ m^{0}+m^{1}+m^{2}+m^{3}+\ldots+m^{h-1} $$
- 高度为 h 的 m 叉树最少有 h 结点
- h 层度为 m 的树最少有 个结点(至少保证有一个节点度=m)
- n 个结点的 m 叉树的最小高度(每一层尽可能填满)(度为 m 的数也一样)
(只能对左侧进行上取整)
- 具有n个结点的m叉树的最大高度为n
- 度为m具有n个结点的树的最大高度为n-m+1
二叉树
Base
- 度为 2 的树 - 至少有一个结点的度 = 2 - 不区分
- 二叉树 - 所有的结点的度可以都 < 2 - 严格区分左右子树
- 满二叉树
- 完全二叉树 - 除最后一层其余层都是满的(最后一层可以不满 但必须从左向右排列)- 排满就是满二叉树
性质
叶节点数 = 双分支节点数 + 1
完全二叉树的性质
1.对于 i 结点:$\begin{aligned}&\text{左孩子:}2i\text{ 右孩子:}2i+1\&\text{父亲:}\left\lfloor\frac{i}{2}\right\rfloor\end{aligned}$
2.$\text{最后一个分支结点的编号是}\left\lfloor\frac{n}{2}\right\rfloor$ 后面的都是叶节点
3.最多只可能有一个度为 1 的结点
4.叶结点只可能在最后两层出现
5.高度 节点数为 n
存储
顺序存储
- 对于非完全二叉树 不存在结点占位 具有相同规律 但会有空间的浪费
- 最坏情况 - 左右单支数
链式存储 - 二叉链表
- 空指针的个数 = 节点数 + 1
- (n个结点2n个指针,除了根结点其它n-1个结点被指针指着,所以有n-1个指针指向了实际结点)
struct BTNode{
char data;
BTNode *lchild,*rchild;
//C语言中 struct BTNode *lchild,*rchild;
}BTNode;
- 若要经常找父亲 - 三叉链表
struct BTNode{
char data;
BTNode *lchild,*parent,*rchild;
}BTNode;
遍历
- 前序遍历(先序遍历) - 根左右 - 深度优先搜索
- 中序遍历 - 左根右
- 后序遍历 - 左右根
- 层序遍历 - 广度优先搜索
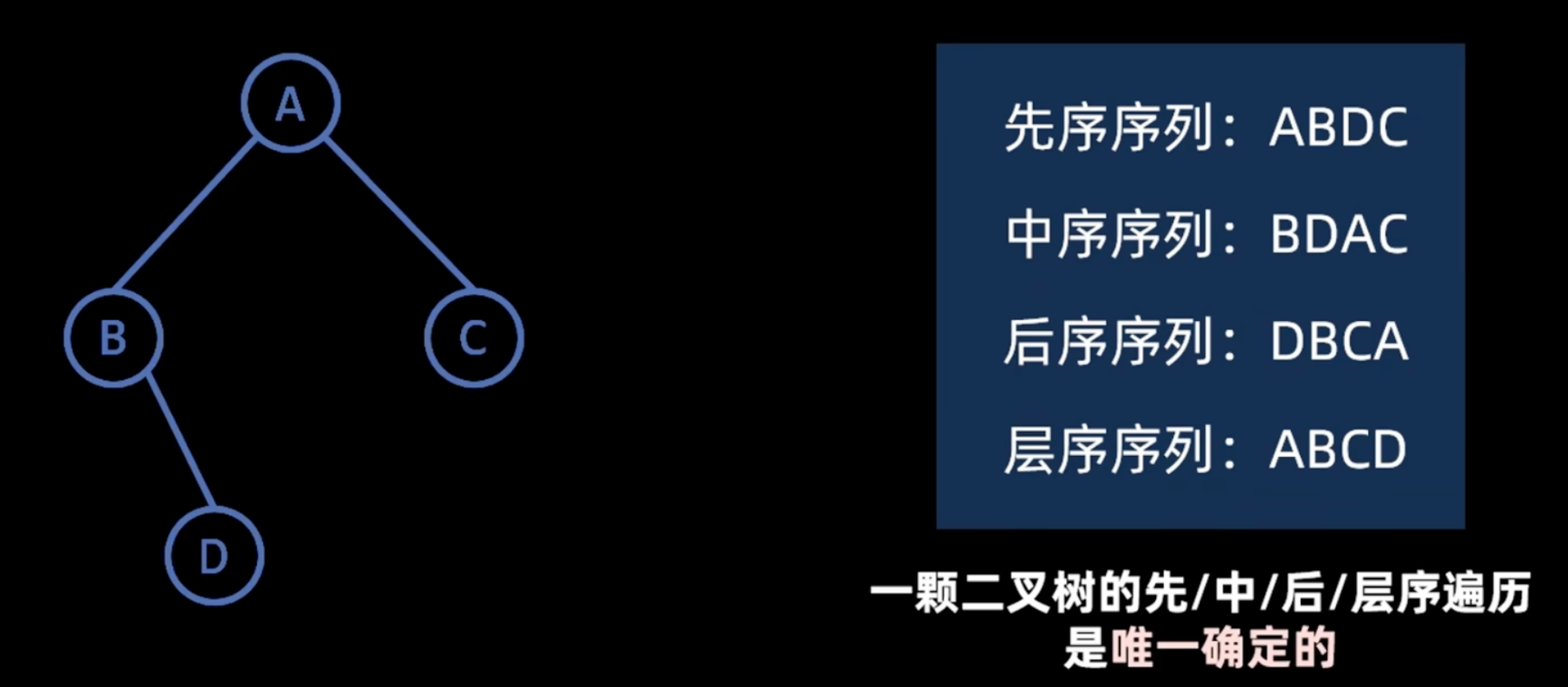
image-1
- 先序序列/后序序列 只可确定根结点
- 中序序列 只要知道了根 就可以划分左右字数
- 层序序列 可确定根节点
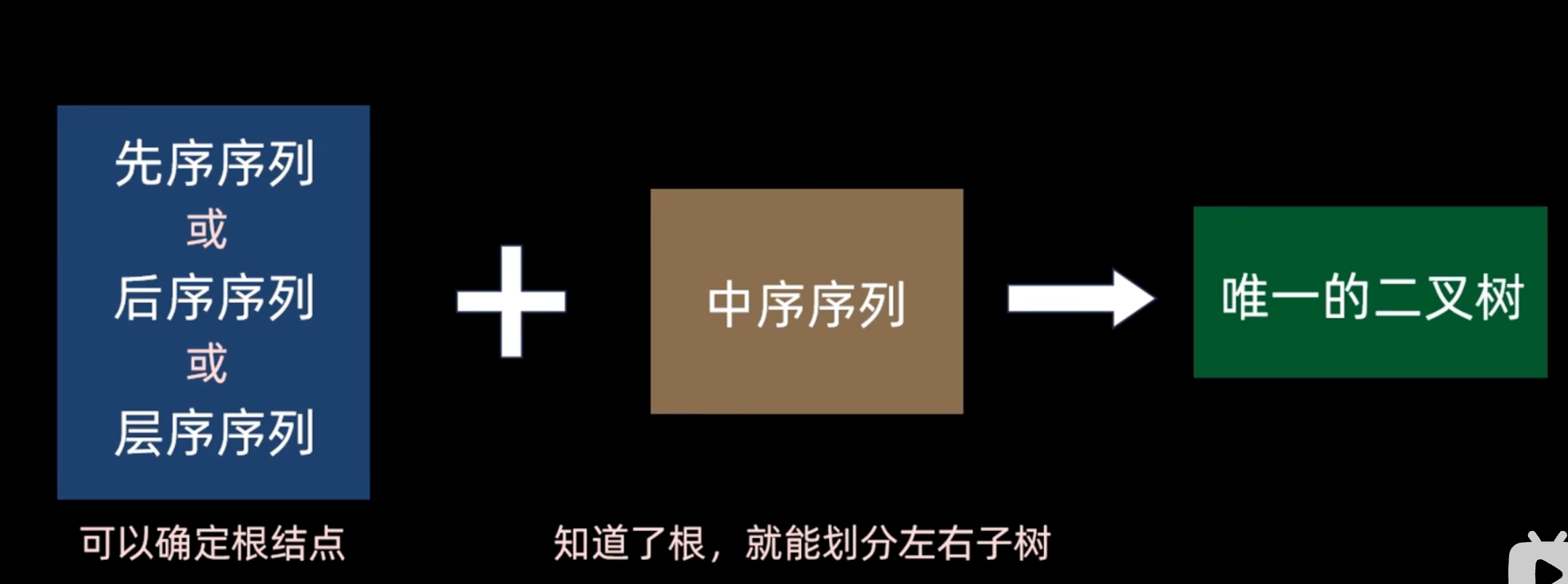
image-2
线索二叉树
- 正常使用二叉链表 不方便寻找一个节点的前驱和后继 只能通过遍历记录
- 但是有大量(n+1)的空指针被浪费了 可以将其利用
- 左空指针指向前驱 右空指针指向后继
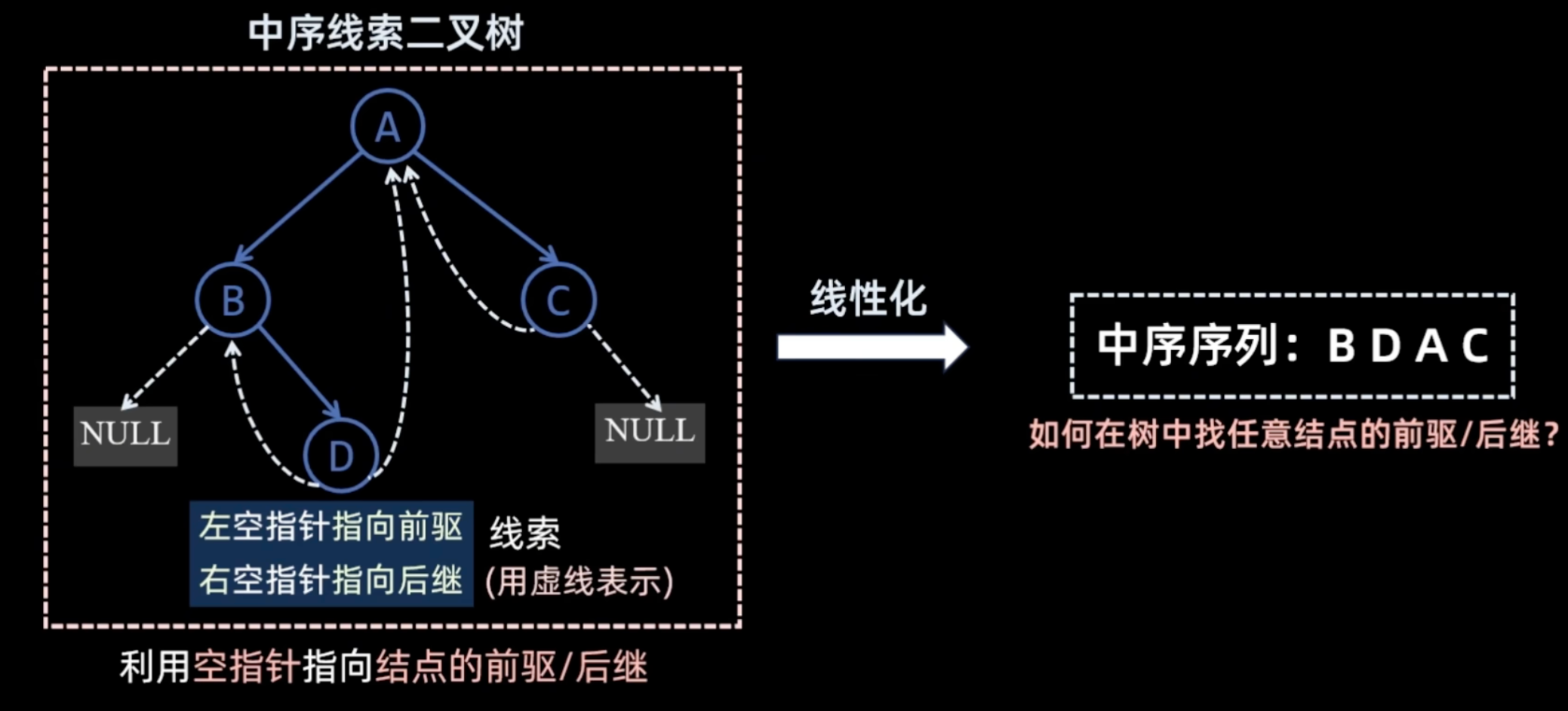
image-3
struct BTNode{
char data;
BTNode *lchild,*rchild;
bool ltag,rtag;//true时表示指向前驱后继
}BTNode;
先序线索化
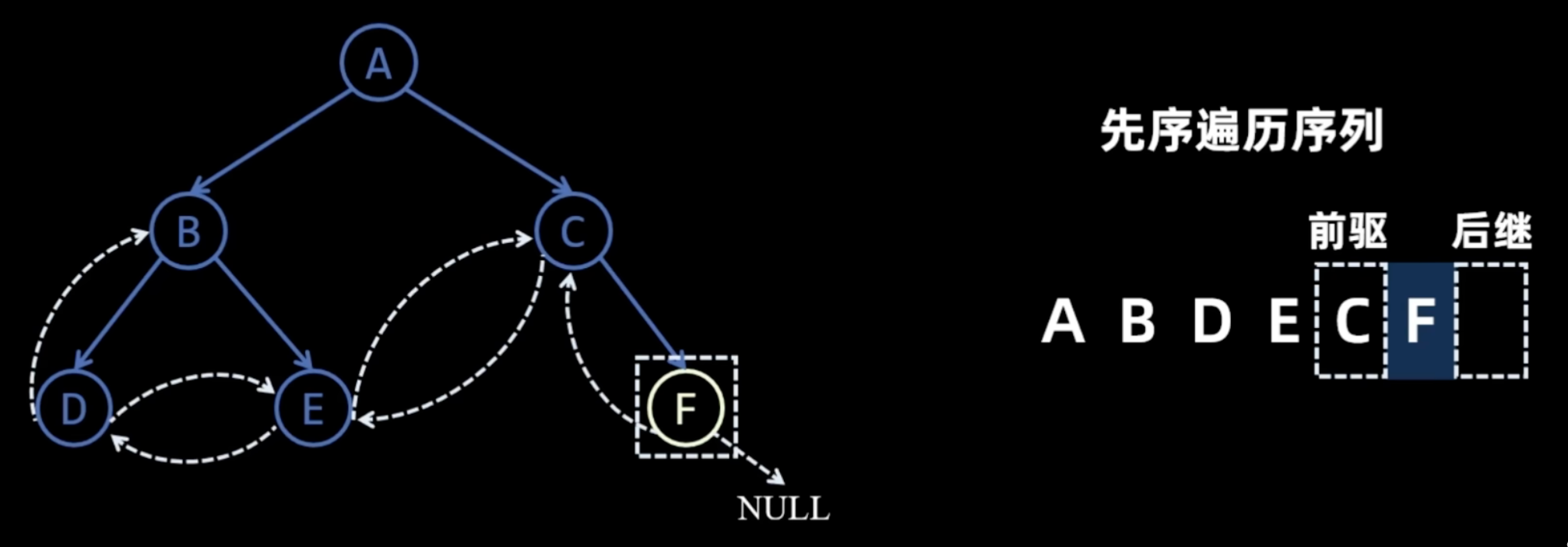
image-4中序线索化
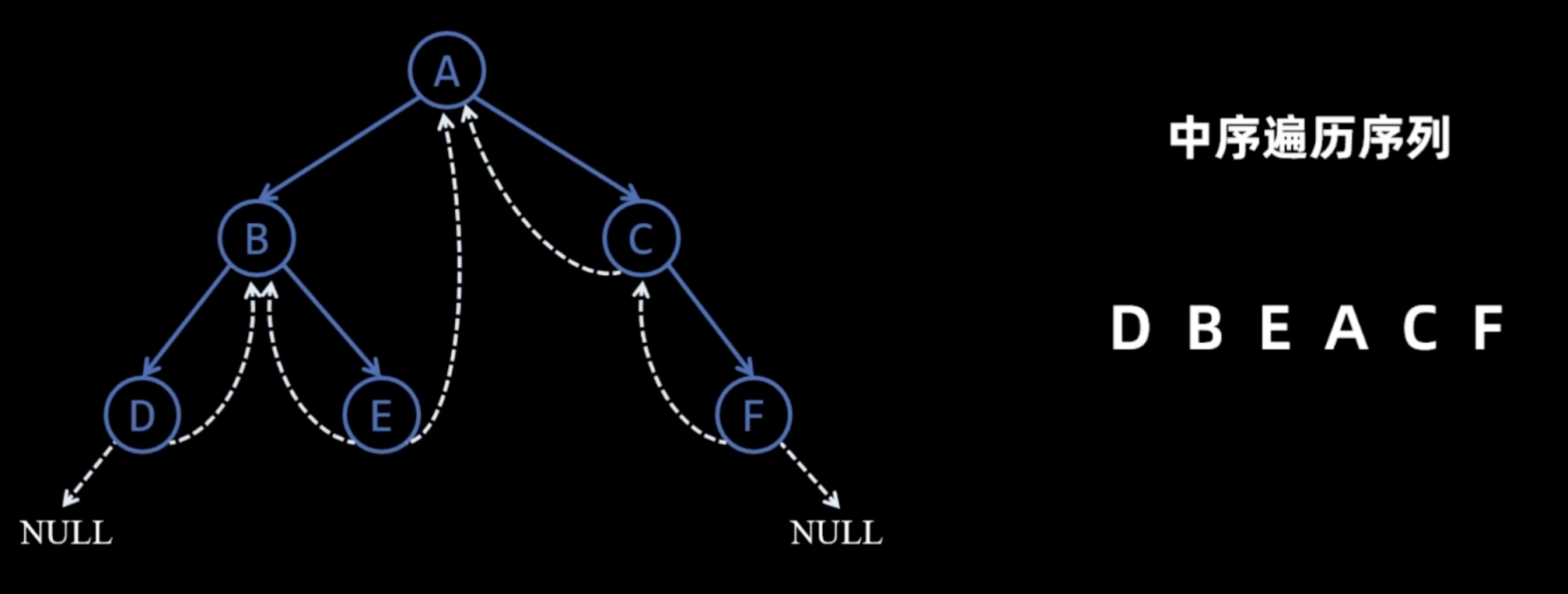
image-5
- 后序线索化
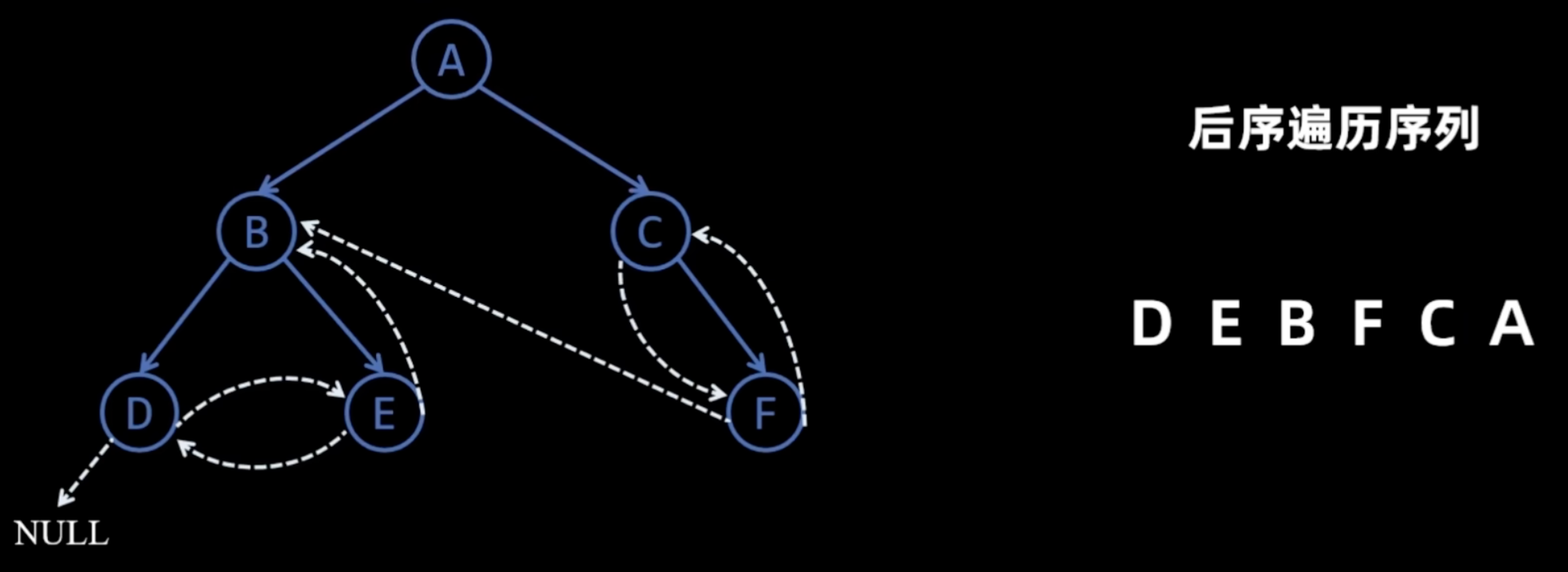
image-6
- 找中序前驱
- ltag = 1
- ltag = 0 从左子树的根开始沿着右孩子不断向下直到没有右孩子(不一定是叶节点)
- 找中序后继
- rtag = 1
- rtag = 0 右子树最左下结点
- 中序/先序优点 省去栈空间
- 找先序前驱
- ltag = 1
- ltag = 0
- 如果 root 无前驱
- 如果是其父的左孩子 前驱为其父
- 如果是其父的右孩子且没左兄弟 前驱为其父
- 如果是其父的右孩子且有左兄弟 前驱为左兄弟子树中最后一个访问的
- (都需要找父亲 故都需要遍历 无法直接找到)
- 找先序后继
- rtag = 1
- rtag = 0
- 有左孩子 后继为左孩子
- 无左孩子 后继为其右孩子(必有右孩子 要不rtag = 1)
- 找后序前驱
- ltag = 1
- ltag = 0
- 有右孩子 前驱为右孩子
- 没有右孩子 前驱为左孩子(必有左孩子 要不ltag = 1)
- 找后序后继
- rtag = 1
- rtag = 0
- root 无后继
- 是其父的右孩子 后继为其父
- 是其父的左孩子且没有右兄弟 后继为其父
- 是其父的左孩子且有右兄弟 后继为其父右子树后序遍历的第一个结点
- (都需要找父亲 故都需要遍历 无法直接找到)
先序线索二叉树无法有效查找先序前驱 后序线索二叉树无法有效查找后序后继 后序线索二叉树的遍历仍需要栈的支持
树的存储
双亲表示法
找父亲容易
struct Node{
char data;
int parent;/
}BTNode;
孩子表示法
顺序存储 + 链式存储(类似图的领接表)
孩子兄弟表示法/二叉树表示法
用二叉链表的形式存储
struct Node{
char data;
Node *firstchild;
Node *nextsibling;//右兄弟
}Node;
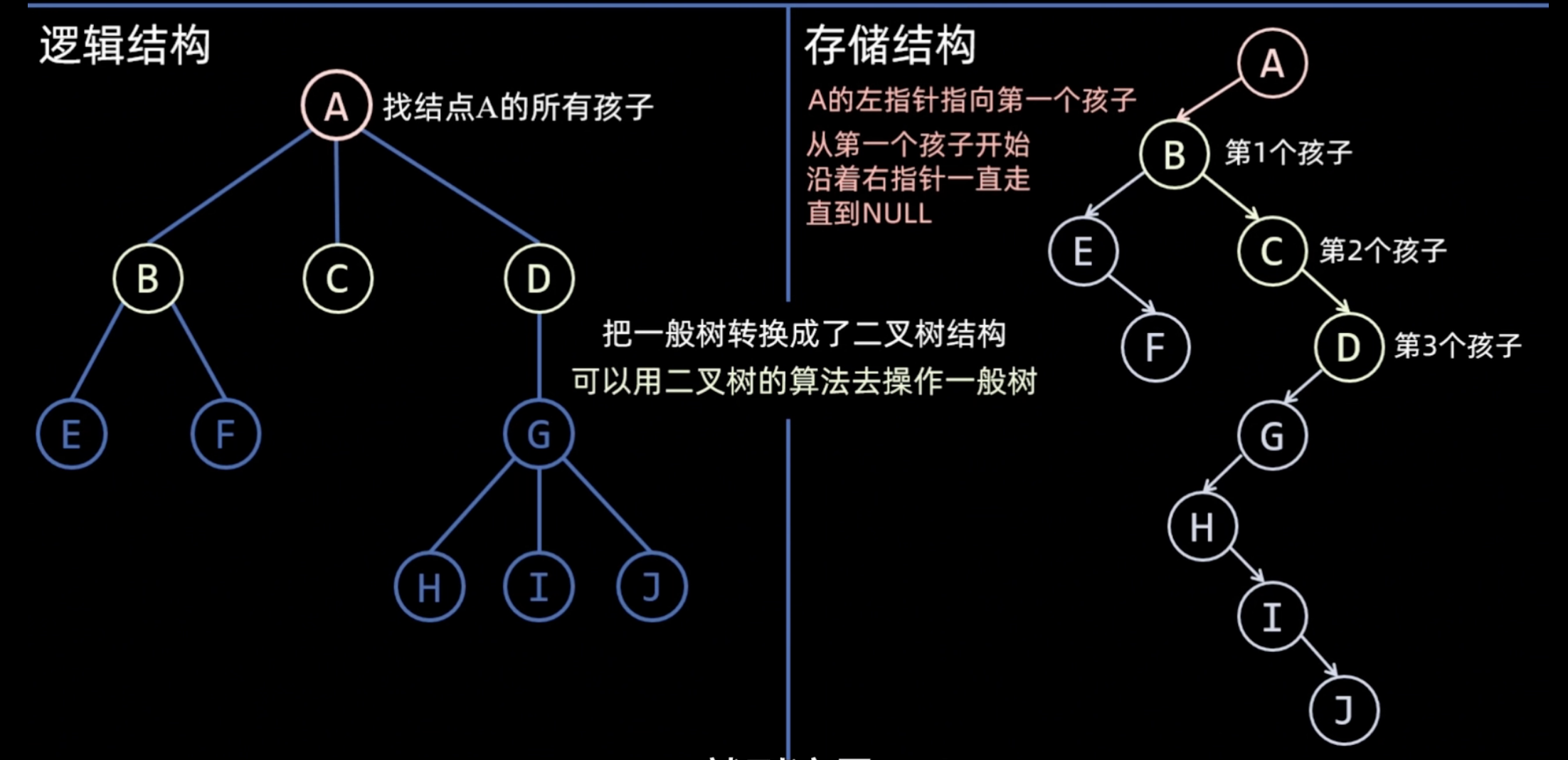
image-66
树转换成二叉树
如上 使用孩子兄弟表示法
森林转换成二叉树
如上 先一次把每棵树转换成二叉树 再把每棵二叉树的根接到前一个根的右指针上 (统一)
相反(沿着右指针)拆成若干二叉树
树的遍历
先根遍历
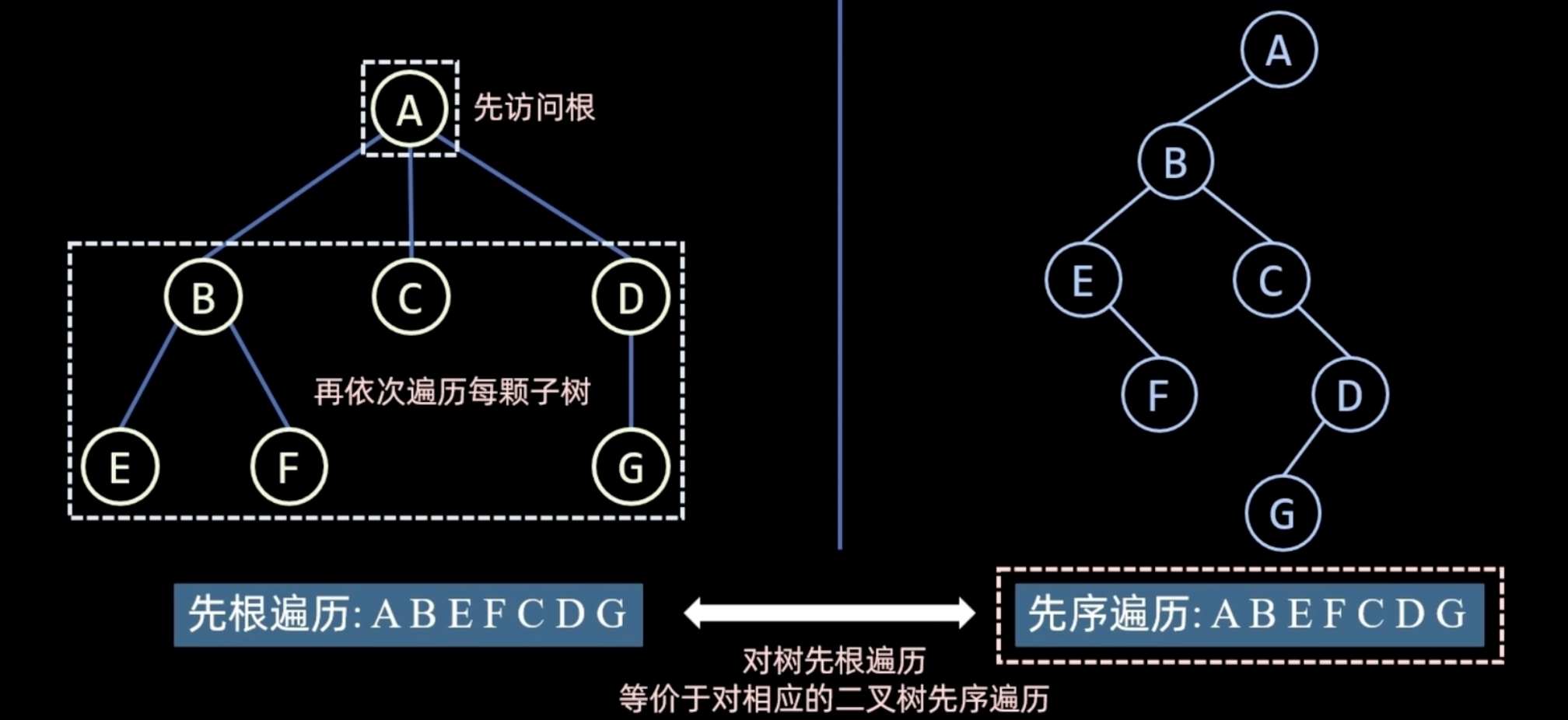
image-9
后根遍历
先依次遍历每个子树 在访问根
对应相应的二叉树的中序遍历
森林遍历
- 先序遍历 同上
- 中序(后序)遍历 等价于对应二叉树的中序遍历
并查集
Find操作:查询元素属于哪个集合
- Union操作:合并两个元素所属的集合
- 可以用树表示 根节点的编号就代表集合
- 其他节点指向父亲 根节点指向自己
vector<int> p;
void Init(int n){
p.resize(n);
for(int i = 0;i < n;i++) p[i] = i;//s[i] = 1,h[i] = 1;
//p[i] = -1;
}
int find(int x){
if(p[x] == x) return x;//p[x] < 0
//路径压缩
else return p[x] = Find(p[x]);//优化效率find(p[x])
}
void Union(int x,int y){
int rootx = Find(x);
int rooty = Find(y);
if(rootx != rooty){
//p[rootx] = rooty;
//按秩合并
//按树的高度合并
//其中路径压缩可能会改变树的高度
//此时 h 数组记录的高度是估计的高度 仅使用按高度合并可以把树的高度控制在 logn 以内
if(h[rootx] < h[rooty]) p[rootx] = rooty;// = rootx
else if(h[rootx] > h[rooty]) p[rooty] = rootx; // = rooty
else{
p[rootx] = rooty;
h[rooty]++;//--
}
//按树的大小合并size
//优先将小树合并到大树上 合并后 s 叠加
if(s[rootx] <= s[rooty]){
p[rootx] = rooty;
s[rooty] += s[rootx];
}else{
p[rooty] = rootx;
s[rootx] += s[rooty];
}
}
}